
The algorithm that is very powerful and is very widely used both within industry and academia is called the support vector machine. SVMs are used for Classification that is the most popular case, but they can also be used for other types of regression machine learning problems. Many people call SVM as large margin classifier and here let’s dive deep into why it was named like that.
We are trying to learn the mapping between the labels and the data and if we learn the mapping that is a function which represents the relationship between these variables, if we learn this function then our machine learning model had done its job. Then we can use this function to predict new data points.
To sum up: The hypothesis can be thought of as a machine that gives a prediction y on some unseen input x. The parameters of the hypothesis are learned.
Why are Support Vectors Machines called so?
The Support Vector Machine helps us create the hyperplane. The way we build this hyperplane or this decision boundary between the classes is by maximizing the Margin. Points in each of the classes that are closest to the decision boundary, we can say that these specific data points are “supporting” the hyperplane are called Support Vectors.
which hyperplane is better?
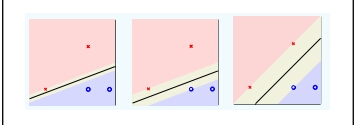
Obviously, the last one is the best choice!
Why should we choose a large margin?
Maximizing the margin seems good because points near the decision surface represent very uncertain classification decisions: there is almost a 50% chance of the classifier deciding either way. A classifier with a large margin makes no low certainty classification decisions. This gives you a classification safety margin: a slight error in measurement or a slight document variation will not cause a misclassification.
we prefer a large margin (or the right margin chosen by cross-validation) because it helps us generalize our predictions and perform better on the test data by not overfitting the model to the training data.
The classification can be bi-classification (only 2 different classes i.e., 0 or 1) or multi-class classification(more than 2 classes).
In multi-class classification:
- In decision_function_shape parameter for SVM, the default is OVR (one vs rest)
- One vs one (OVO).
When to choose SVM:
- When we have more features and fewer datasets (we can choose SVM without kernel i.e., linear kernel)
- When we have fewer features and intermediately sized datasets(we can choose SVM with the Gaussian kernel)
However other Algorithms Random Forests deep Neural Networks etc require more data but almost always come up with a very robust model.
FOR CODE:
https://github.com/neha-duggirala/100DaysOfMLCode/tree/master/SupportVectorMachine
REFERENCES:
https://www.coursera.org/learn/machine-learning/lecture/3eNnh/mathematics-behind-large-margin-classification
https://onionesquereality.wordpress.com/2009/03/22/why-are-support-vectors-machines-called-so/

This website was… how do you say it? Relevant!! Finally I have found something that helped me. Many thanks!|
LikeLike
At this time I am going away to do my breakfast, once having my breakfast coming again to read other news.|
LikeLike